Trajectory data¶
Section author: Zachary Jerome <zjerome@umich.edu>
Overview¶
The MTLDP trajectory model (mtldp.traj) provides a uniform framework for processing trajectory data after it has been loaded and pre-processed in basic processing. Most data sources provide connected vehicle data through a list of points. However, this is usually not a very helpful format and any sort of meaningful analysis will require a significant amount of processing. The MTLDP organizes connected vehicle data in a three-level format that can be easily manipulated and analyzed for a variety of research applications. These attributes are also stored in a Pandas data framework, and can be visualized and queried depending on the research needs.
Structure¶
After basic processing, trajectory data is stored in a standard in-storage format. In post-processing, the MTLDP organizes the in-storage trajectory data in a three-level framework:
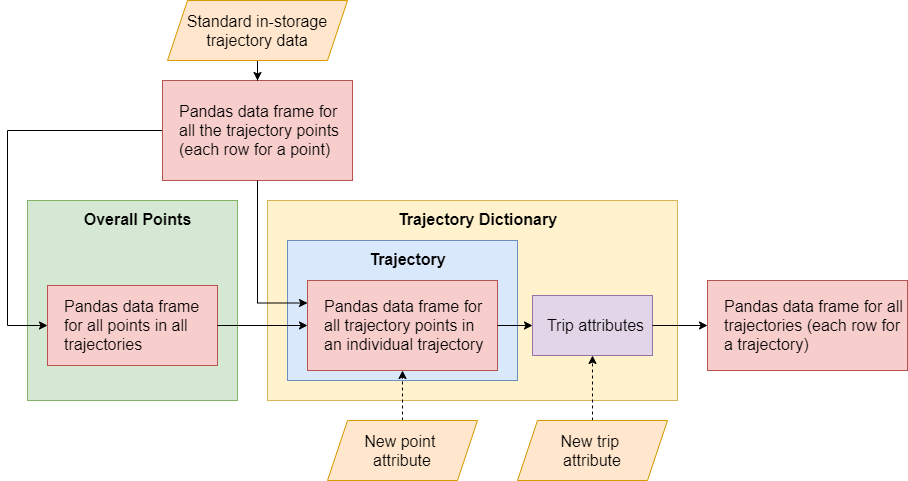
Each level (trajectory point table, trajectory, and trajectory dictionary) is represented through a class object: mtldp.mtltrajs.OverallPoints,
mtldp.mtltrajs.Trajectory, mtldp.mtltrajs.TrajectoryDict. Standard in-storage trajectory data is first
converted into a pandas data frame either through a data adapter or standard trajectory file. If the data contains only
one trajectory, a trajectory class can be initiated. Otherwise, a trajectory table should be initiated. From there, a dictionary
of trajectories can be created by splitting all of the points in the trajectory table
into their respective trajectories. The trajectories can be further split by time and distance gaps if needed.
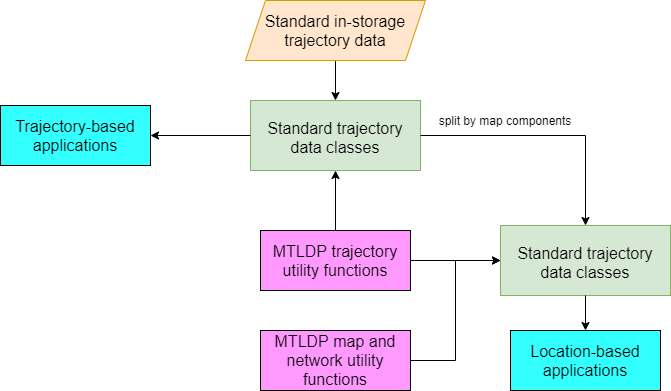
From the standard trajectory data classes, the data can be easily prepared for both trajectory-based and location-based applications. The figure below illustrates how these standard trajectory data classes can be utilized for trajectory-based and location-based applications. These applications can be enhanced through trajectory, map, and network utility functions such as filtering, plotting, visualization, and modeling.
Pandas¶
In the loading process, trajectory points are stored in a pandas data frame. This data frame can be filtered at the trajectory level so that each trajectory object contains a data frame that reflects point level attributes in that trajectory. New columns can also be added to a data frame for a new point attribute. A new data frame can also be generated in the Trajectory Dictionary that contains trajectory level information.
Note
The overall point data frame can contain point-level information for multiple trajectories. This is useful if you want to query specific data points and don’t want to iterate over all of the trajectories in the collection.
Fast Map Matching¶
The mtldp.mtltrajs.FmmModule class matches trajectory points to the map data using Fast Map Matching. The MTLDP
trajectory model is designed to easily integrate the standard trajectory structure with FMM. This includes
creating the necessary input files and matching the FMM output file with the trajectory structure.
Map Attribute Matching¶
After map matching, other map data stored in the mtldp.mtlmap.Network can be matched to the trajectory points.
These functions use the matched segment_id from FMM and trajectory movements to match other map attributes to the
trajectory point. These map attributes include upstream and downstream intersection ids, link id, and upstream
and downstream movement ids.